
Transfer Learning, Teknik Canggih dalam Deep Learning yang Menghemat Waktu dan Sumber Daya
Eradt >> Artificial Intelligence & Machine Learning>> Transfer Learning, Teknik Canggih dalam Deep Learning yang Menghemat Waktu dan Sumber Daya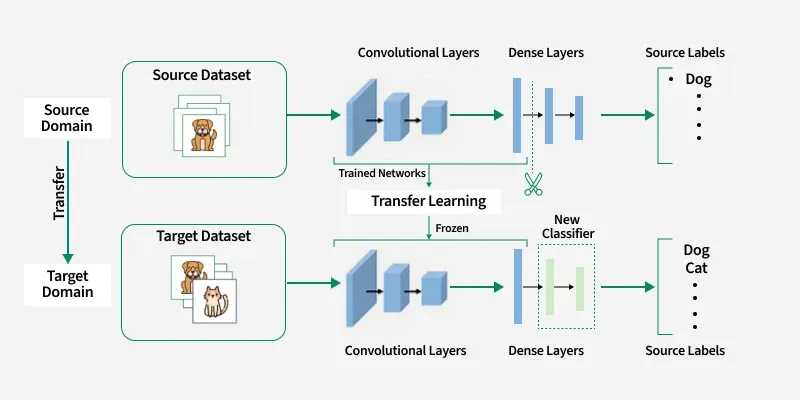
Transfer Learning, Teknik Canggih dalam Deep Learning yang Menghemat Waktu dan Sumber Daya
eradt.com – Transfer Learning adalah salah satu teknik paling powerful dan populer di bidang kecerdasan buatan (AI) dan machine learning, khususnya deep learning. Alih-alih melatih model neural network dari nol (from scratch), kita memanfaatkan model yang sudah dilatih sebelumnya pada dataset besar untuk menyelesaikan tugas baru yang mirip. Teknik ini sangat berguna ketika data pelatihan kita terbatas atau komputasi terbatas.
Apa Itu Transfer Learning?
Transfer Learning adalah proses di mana pengetahuan yang diperoleh dari satu tugas (task source) dipindahkan ke tugas lain (task target). Model pretrained yang biasanya dilatih pada dataset raksasa seperti ImageNet (untuk gambar) atau Common Crawl (untuk teks) menjadi dasar, lalu kita fine-tune hanya sebagian kecil lapisannya untuk tugas spesifik kita.
Contoh sederhana: Seorang dokter mata ingin membuat model untuk mendeteksi penyakit retina dari foto mata. Alih-alih melatih model dari nol dengan ribuan foto retina (yang sulit didapat), ia mengambil model seperti ResNet-50 atau EfficientNet yang sudah dilatih pada jutaan gambar umum, lalu hanya menyesuaikan lapisan terakhir untuk mengenali pola penyakit retina.
Mengapa Transfer Learning Sangat Populer?
- Menghemat waktu pelatihan — Melatih model besar dari nol bisa memakan hari atau minggu, bahkan dengan GPU kelas atas.
- Mengatasi keterbatasan data — Banyak kasus nyata memiliki dataset kecil (misalnya 100–1.000 sampel), yang rentan overfitting jika dilatih dari nol.
- Performa lebih baik — Model pretrained sudah belajar fitur umum (tepi, tekstur, bentuk untuk gambar; sintaksis, semantik untuk teks) sehingga hasil akhir sering lebih akurat.
- Hemat biaya komputasi — Cocok untuk startup, peneliti, atau pengguna dengan hardware terbatas.
Cara Kerja Transfer Learning (Dua Pendekatan Utama)
- Feature Extraction (Frozen Base Model)
- Lapisan awal (base model) dibekukan (tidak di-update).
- Hanya lapisan terakhir (classifier) yang dilatih ulang dengan data baru.
- Cocok ketika dataset target sangat kecil.
- Fine-Tuning
- Lapisan awal tetap dibekukan, tapi lapisan akhir (atau beberapa lapisan terakhir) di-unfreeze dan dilatih ulang.
- Learning rate biasanya sangat kecil (misalnya 1e-5) agar tidak merusak bobot yang sudah baik.
- Memberikan hasil lebih baik ketika ada cukup data.
Model Pretrained Populer yang Sering Digunakan
Untuk Computer Vision (Gambar):
- ResNet (50, 101, 152)
- EfficientNet (B0–B7)
- MobileNetV2/V3 (ringan, cocok untuk mobile)
- Vision Transformer (ViT)
- ConvNeXt
Untuk Natural Language Processing (Teks):
- BERT, RoBERTa, DistilBERT
- GPT-2, GPT-3 (via OpenAI API)
- T5, BART
- IndoBERT, IndoGPT (untuk bahasa Indonesia)
Untuk Audio/Speech:
- wav2vec 2.0, HuBERT
- Whisper (OpenAI)
Contoh Penerapan Transfer Learning di Dunia Nyata
- Deteksi penyakit tanaman — Petani menggunakan model pretrained untuk mengenali penyakit daun dari foto ponsel.
- Analisis sentimen bahasa Indonesia — Menggunakan IndoBERT untuk mengklasifikasikan ulasan produk Tokopedia atau Shopee.
- Aplikasi mobile — Face recognition atau object detection di aplikasi kamera ponsel.
- Medis — Deteksi tumor dari MRI/CT scan dengan dataset terbatas.
Kelebihan dan Kekurangan Transfer Learning
Kelebihan:
- Hasil cepat dan akurat dengan data sedikit
- Mengurangi kebutuhan komputasi besar
- Mudah diimplementasikan dengan library seperti TensorFlow, PyTorch, Hugging Face
Kekurangan:
- Tidak selalu optimal jika tugas target sangat berbeda dari tugas source (domain shift)
- Model pretrained besar bisa memakan memori cukup banyak
- Risiko overfitting jika fine-tuning tidak hati-hati
Transfer Learning telah merevolusi cara kita membangun model AI di era data terbatas. Dengan memanfaatkan model pretrained yang sudah “terdidik” pada miliaran sampel, siapa saja—mulai dari mahasiswa hingga perusahaan besar—bisa menciptakan aplikasi AI berkualitas tinggi dengan waktu dan biaya minimal. Di masa depan, teknik ini akan semakin penting seiring berkembangnya model-model foundation yang lebih besar dan lebih umum.